Ich setze Syntaxhighlighter evolved ein, der eckige Klammern als Markup verwendet:

So sieht dann das Ergebnis aus:

Ich setze Syntaxhighlighter evolved ein, der eckige Klammern als Markup verwendet:
So sieht dann das Ergebnis aus:
1.a.) Download .msi von WinAppDriver und installiere.
1.b.) Dann per cmd starten: C:\Program Files (x86)\Windows Application Driver\WinAppDriver.exe
2.) In Visual Studio:
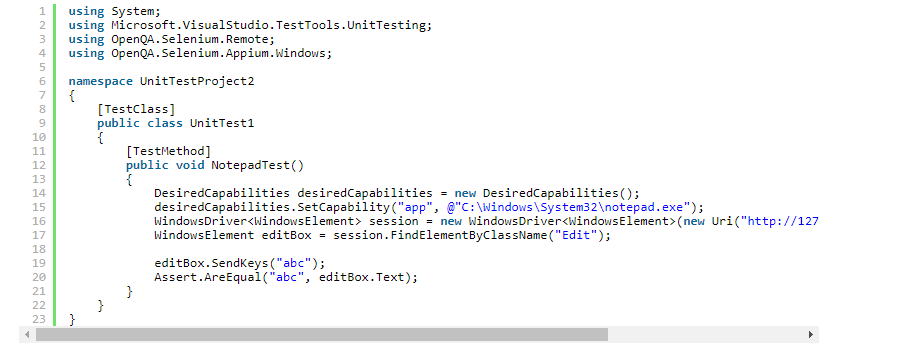
using System;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using OpenQA.Selenium.Remote;
using OpenQA.Selenium.Appium.Windows;
namespace UnitTestProject2
{
[TestClass]
public class UnitTest1
{
[TestMethod]
public void NotepadTest()
{
DesiredCapabilities desiredCapabilities = new DesiredCapabilities();
desiredCapabilities.SetCapability("app", @"C:\Windows\System32\notepad.exe");
WindowsDriver<WindowsElement> session = new WindowsDriver<WindowsElement>(new Uri("http://127.0.0.1:4723"), desiredCapabilities); // 127.0.0.1:4723 zielt auf den WinAppDriver-Server
WindowsElement editBox = session.FindElementByClassName("Edit");
editBox.SendKeys("abc");
Assert.AreEqual("abc", editBox.Text);
}
}
}
.
3.) Mit Inspect kann man die Pfade ermitteln. Liegt nach Installation von Windows SDK 8.1 z.B. hier: C:\Program Files (x86)\Windows Kits\10\bin\x86
.
.
.
Download den Sourcecode
.sln per Visual Studio öffnen
Win 10 API installieren, wozu man aufgefordert wird. Anschließend erscheint eine solche Meldung:
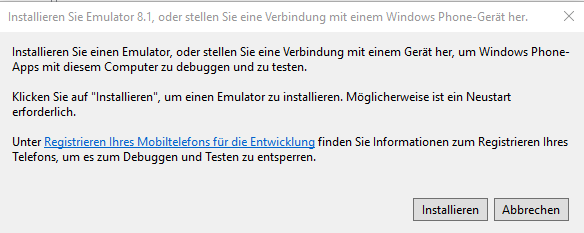
Windows-Suche: Für Entwickler-Einstellungen -> Entwicklermodus (bzw. Apps querladen falls durch Group policy gesperrt) einschalten.
Scheiterte evtl. an der group policy bei meinem Arbeitsplatzrechner, denn bei der Win 10 – VM gab es diesen Fehler nicht:

[Disclaimer: Ich bin kein Steuerberater und übernehme für die Richtigkeit des Folgenden keine Haftung]
In drei verschiedenen Foren habe ich gelesen, dass man die rein privaten Umsätze im gemischten Konto als Privateinlagen/Privatentnahmen buchen soll (Quelle 1, Quelle 2, Quelle 3).
Um Privateinlage/Privatentnahme zu buchen: bei Art der Ausgabe wird Privat eingetragen. (Quelle: Lexoffice)
[Folgendes Verfahren ist nicht mehr erlaubt und steht hier nur noch aus dokumentarischen Gründen!]
Anfrage an lexoffice-support
Meine Geschäftsausgaben laufen auch über mein privates Konto. Dieses habe ich bei Lexoffice hinterlegt und aktualisiere dieses. Wie kann ich nun die rein privaten Buchungen entsprechend wegmachen, damit diese nicht mehr in die Buchhaltung reinwirken?
Antwort von lexoffice
Um nicht benötigte Banktransaktionen auszublenden, haben Sie die Wahl eine einzelne oder sämtliche Banktransaktionen auszublenden.
Um eine einzelne Banktransaktion auszublenden, klicken Sie die entsprechende Transaktion an und wählen Sie den Button „Ausblenden“.
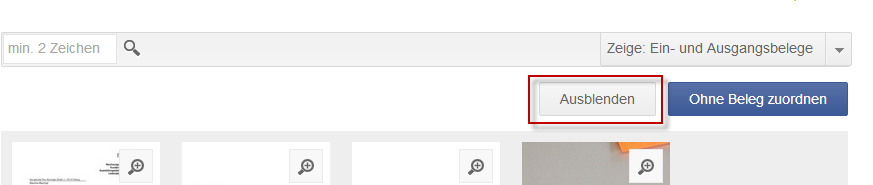
Um sämtliche Banktransaktionen auszublenden, klicken Sie bitte auf „Nicht zugeordnete ausblenden“. Sie können max. 500 Banktransaktionen auf einmal ausblenden.

Um eine Übersicht aller ausgeblendeter Transaktionen zu sehen, nutzen Sie den Filter „Zeige: Ausgeblendete“.
In dieser Übersicht aller ausgeblendeter Transaktionen können Sie bei Bedarf einzelne oder alle wieder einblenden.
